Advanced File Search
Bulk Text Extraction and File Migration Tool
Challenge: Many of CobbleStone®’s customers have numerous legal and contract documents that may or may not have been cataloged well or entered into a database to be tracked and searched. The task of extracting data fields, text, and clauses may be an arduous one. In many cases, help streamlining the data extraction process is required. Typical data that are requested to be extracted include but are not limited to: customer/vendor (counterparty) name, address, city state, zip, contract effective date, contract expiration, title, and contract owner (legal professional) name. For more advanced projects, extraction of clauses and terms may pose a challenge. Image if many files are in a folder system or network file system. It may be difficult to locate a contract document and/or analyse the data from the spreadsheet (data) to the actual contract document/file.
CobbleStone® offers a combination of services and software tools to help with the extraction of metadata and clause text from files and bulk importing the files and metadata to Contract Insight. These tools in include, Bulk File Migration Tool, Bulk Text Extraction, Data Import Tools for metadata import and update, and Batch Contract Entry.
In this section, we will cover the Bulk File uploader tool (available via professional services from CobbleStone®) and the Bulk Text Extraction tool (available within the Contract Insight Enterprise Software application).
A typical bulk extraction process includes the following activities:
Bulk File Importer Tool
The Bulk File Importer was designed to CobbleStone® personal via professional services the ability to bulk upload files to a client's Contract Insight Enterprise Software SaaS database without requiring direct access to the database server. The bulk file importer process is discussed separately in this documentation wiki.
Bulk Text and Clause Extraction
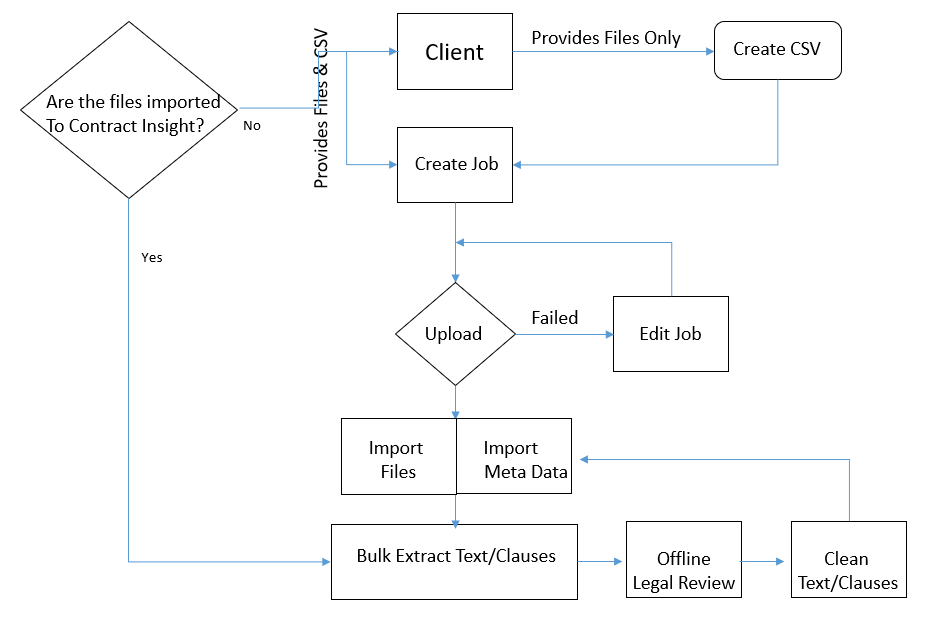
The steps below focus on the extract text and clauses from contract documents after the files have been imported to Contract Insight Enterprise. This process requires the Enterprise Edition, text-based files imported to the Contract repository, good quality text in the documentation, administrative access, and having the OCR tool enabled.
1. Log into the system as a System Admin User.
2. Navigate to Report/Searches - Risk Analysis - Risk Mitigation Tools.
.png)
3. Select the Risk Review with Mining Contract Language option. This is used to perform bulk text extraction from text-based documents.

4. The Text Extraction Tools screen appears as seen below. Select the Parent Object. In this case we are extracting text from files on the Contract records area, so we selected Contract Details.
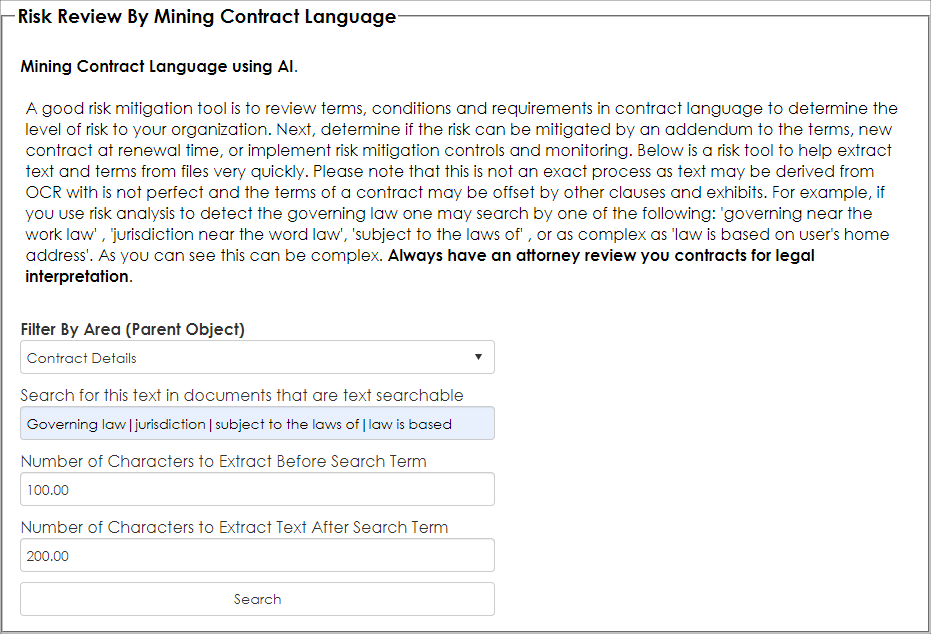
5. Tell the engine what text or phrases you are searching for and how many characters to extract from the left of the found text to the right of the fond text or phrase. In this example ware are searching for governing law, jurisdiction, subject to the laws of, and law is based as our search text-phrase seen below. Separate the search terms-phrases with the pipe character (|).
We entered 100 for the number of characters to extract before the found term and 200 characters for the number characters to extract after the found term (if the term or phrase is found).
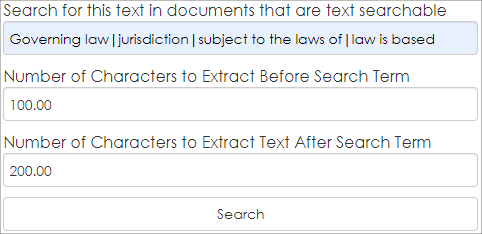
6. Click Search.
The system attempts to search the files attached to contract records that have text in the document.
Note: it is important that the files uploaded are text based or have been OCRed to a good quality as text recognition, OCR, and search is not exact. Characters, scanned images, orientations, spacing, font, quality, line separators, and other factors may impact results.
The engine looks at each text document, searched text if text is found, search each page, try to match the search terms or phrases, try to extract the text, and output a column for each text/phrase searched and the results of what was found. If the text extracted is too limiting, broaden the search terms and phrases and search again as typically several passes may be needed.
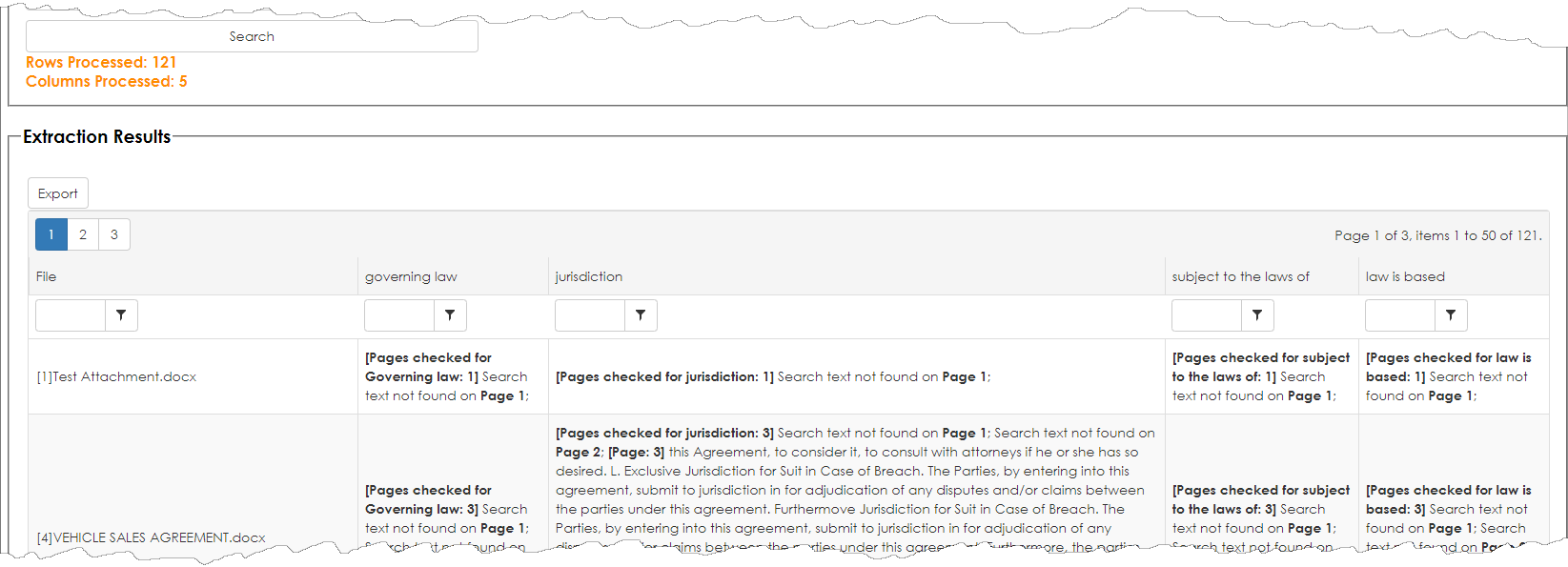
The engine attempts to identify the pages search, if text is found and results. If no text is found, this is indicator to manually review the document as the engine or document did not find text. This is helpful as the legal review team can easily review and determine what the laws may be applicable for this example.
Note: not all results are perfect; an attorney should be retained to perform legal review of legal documents.

Optionally, the user may export the results to Excel. This is useful to clean up the extracted text, send it for legal review, and potentially be used to re-import the data back into Contract Insight.
Below are some sample rows where the bulk extract engine did not have access to the searchable text. Some causes may be the file is an image document and text not searchable, the OCR engine could not OCR, the document is of poor quality or orientation, the files are locked, the files are password protected, the file is corrupted, etc. Each situation is unique and will require legal review by an attorney.

Summary
Data mining and bulk extraction of document text, terms, conditions, and contract language may be useful as good risk review tool. Be aware that this process is not perfect and to use an attorney and your best judgement for each process.
Enable to the OCR Scheduler
Ensure the OCR engine is enabled. To help with text recognition and as required, ensure the OCR engine is enabled and running via the Application Configuration - OCR and Full Text Indexing engine menu item. Check with your CobbleStone® representative for more information.
.png)